[Architecture] DDD 알아보기 - 2

이번 글은 if(kakao)2022의 ㄷㄷㄷ: Domain Driven Design과 적용 사례공유를 보고 옮겨보았습니다.
앞선 글에서는 DDD를 대하는 자세, 개발 방법에 대한 내용이었다면, 이번 글은 카카오 엔터테인먼트의 레거시 시스템을 DDD를 활용한 MSA로 분리하는 과정을 구체적 예시를 들어 설명하고 있었습니다.
1. Bounded Context
비즈니스 업무의 경계를 구분해 놓은 하위 도메인 개념이다. 앞서서 DDD는 분할 정복이라고 말했다. 우리가 가진 문제들이 무엇인지 분할해야 하며, 각각의 문제들을 해결하기 위한 하위 도메인이 Bounded Context이다.
예를 들어 쇼핑몰 시스템이 있다고 하면 주문, 상품, 유저, 배송 등등의 하위 도메인이 있을 것이다. 각각을 해결하기 위한 공간이 Bounded Context이다.
만약 모놀리식 DDD를 MSA로 분리한다고 하면, 이 Bounded Context 경계를 하나씩 분리하면 된다.
2. Context Map
Bounded Context간의 관계를 표현한 그림이다. 서로 의존성을 분리한 만큼, 서로 어떠한 방식으로든 소통해야 한다. 그것이 MSA라면 REST API 같은 웹 통신이 될 수도 있고, 모놀리식 DDD라면 소통을 위한 레이어가 필요하다.
그 관계들을 그림으로 정리해, 시스템 간의 관계를 한 눈에 파악하게 해준다.
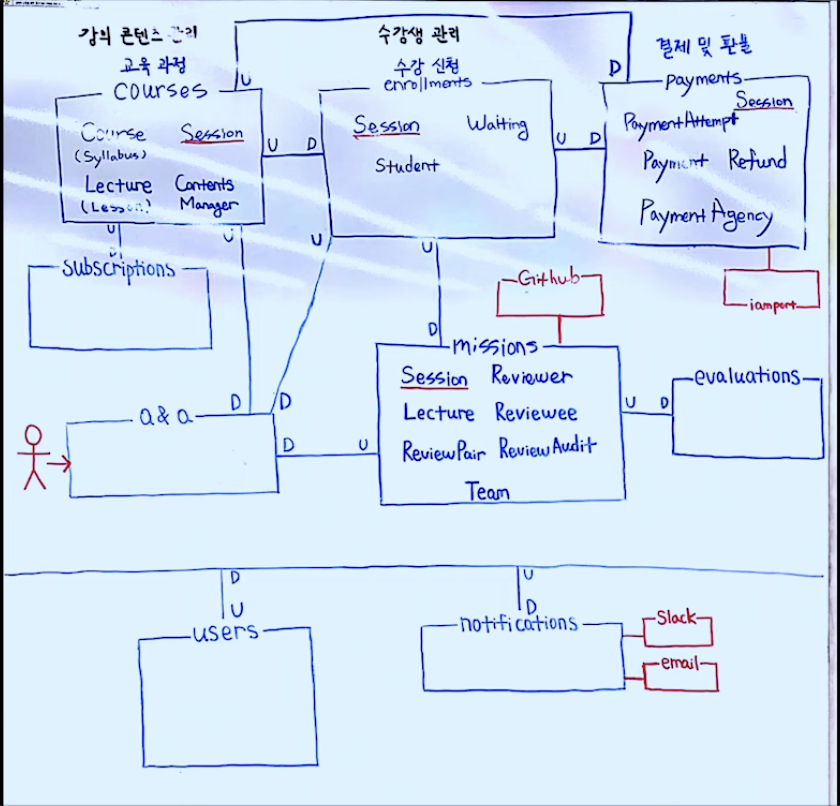
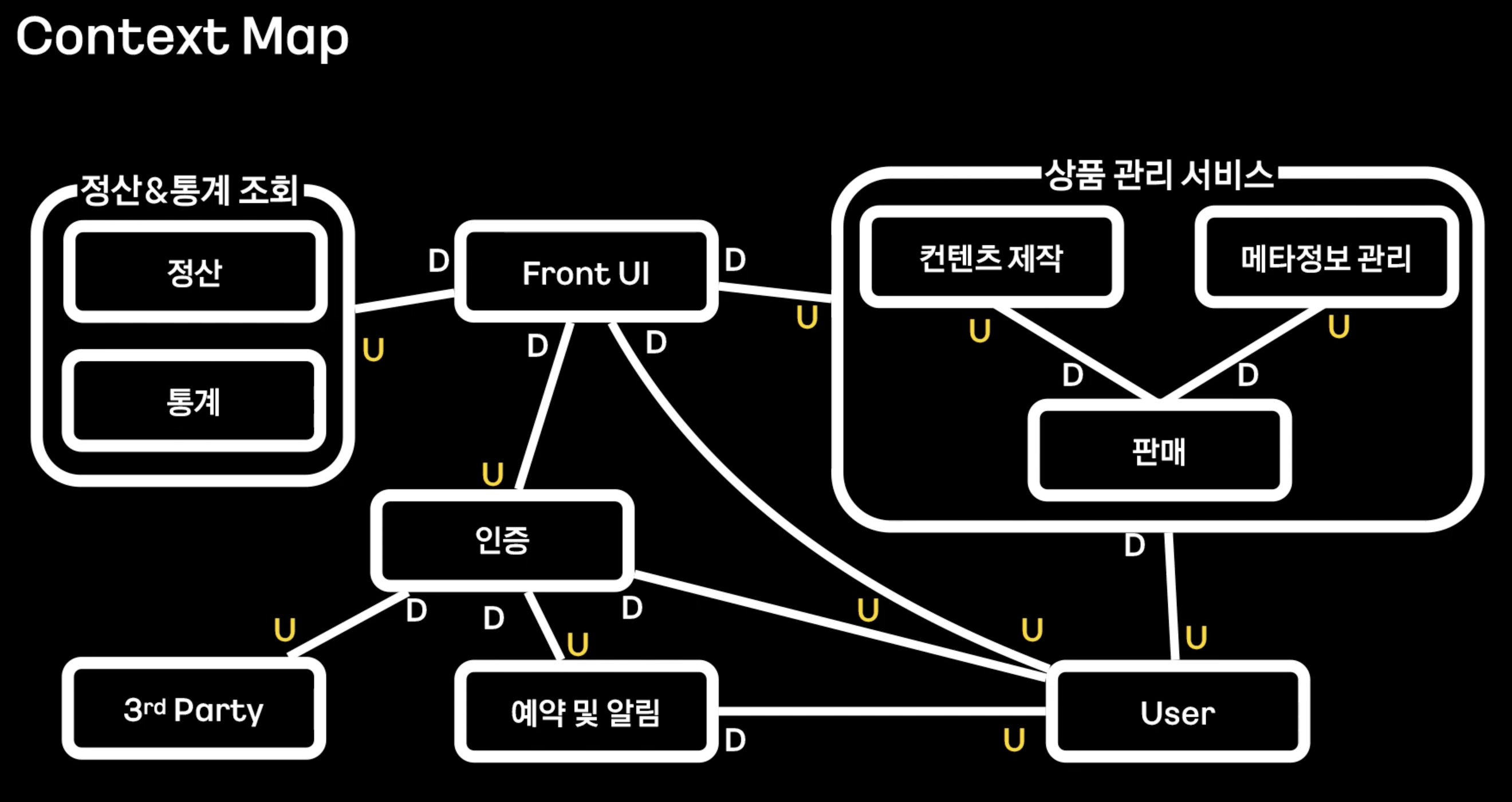
그림에서의 U는 Uptream, 데이터를 전송하는 쪽을 뜻한다. D는 DownStream, 데이터를 받아 소비하는 쪽을 뜻한다.
(이하 사견) 이것을 표시하는 이유는 장애 범위 파악과 소통을 위한 것이라 생각한다. U의 시스템을 다루는 입장에선, 기능 변화가 D에 영향을 줄 수 있다. 이것을 한 눈에 파악할 수 있고, 빠르게 공유 가능하다. D의 입장에선, 우리 서비스에 어떠한 문제가 생긴다면 U쪽이 문제일 수 있다는 생각을 할 수 있다.
3. Aggregate
라이프사이클이 같은 도메인 객체를 한 곳에 모아 둔 집합이자, 데이터 변경의 단위이다.
핵심 규칙은, Aggregate 내부에 대한 데이터 접근은 반드시 Root Entity로만 이루어져야 한다.
영상에서는 VideoProduct라는 도메인으로 설명하는데, 이 안에 포함된 인코딩 정보나, 파일 정보에 대한 변경은 각각으로 불가능하고, 반드시 VideoProduct 를 통해서만 가능하다.
Aggregate를 빡세게 지킬수록, 도메인 로직의 캡슐화가 자연스럽게 이루어진다.
4. 적용 사례
아키텍쳐: Hexagonal
아티텍쳐는 Port(=interface)와 Adaptor(=구현체)로 확실하게 구현 가능한 Hexagonal로 구현했다. Hexagonal에 대한 자세한 설명은 생략한다.
Domain
Product Aggregate의 Root Entity인 Product 를 보여주며 설명한다.
1
2
3
4
5
6
7
public class Product {
...
private ProductSalesInfo productSalesInfo;
private ProductMetaInfo productMetaInfo;
private Content content;
...
}
Product 내부의 정보는 반드시 Product 를 통해서만 변경 가능하다.
예를 들어서 ProductSalesInfo는 아마 테이블을 가진 엔티티겠지만, ProductSalesInfoRepository 나 별도 Service 레이어가 아닌, 반드시 Product 의 도메인 로직으로만 변경되어야 한다.
참고로 Product는 POJO이고, Jpa 엔티티로의 변환은 별도 Mapper 계층을 통해 이루어지고 있었다.
이 외에 영상엔 Hexagonal을 통해 구현한 코드가 있었다. Hexagonal에 대해 다루는 글은 아니니 내용은 생략한다.
5. 장단점
은 총알은 없다. 라는 말이 알려주듯, 모든 문제에 대한 절대적인 해결책은 없는 법이다. DDD 역시 그렇다.
장점
- 보편 언어를 통한 소통으로,
- 복잡한 관계 정리 및 유지보수 향상
- 자동 캡슐화
- 높은 응집도, 낮은 의존도.
단점
- 높은 도메인 이해도 필요
- 구현 코드량 증가
- 높아진 개발 난이도