[Infra] SPOF 극복하기

초보 개발자에겐 서버 인프라를 만들어서 배포하는 것도 매우 힘든 일이다. 하지만 EC2에 서버를 올리고, DB에 연결하기만 하면 서비스를 위한 준비는 끝일까?
우리의 서버는 가끔, 위험한 상황을 마주한다. 그것이 악의적인 트래픽 공격일 수도 있고, 단순히 프로그래밍 실수로 인한 서버 자원 과부하일 수도 있다. 상황은 여러가지다.
하지만 유저가 겪는, 서비스를 이용하지 못한다 라는 불편함은 똑같고, 또 너무나 치명적인 결함이다. 이번 글에선 어떻게 서비스의 가용성을 올릴 수 있는지 가상의 상황을 통해 알아본다.
1. 용어 정의
SPOF (Single Point of Failure)
인프라에서 한 곳이 고장나면, 시스템 전체가 붕괴되는 지점을 말한다.
가용성(Availability)
시스템이 안정적으로 서비스되는 정도를 뜻한다.
AZ (Availability Zone)
2. 예시 인프라
가상의 인프라 모델
- 클라이언트: 브라우저를 통해 접속함.
- DNS: 도메인을 IP 주소로 변환해줌.
- 단일 웹 서버: 사용자의 모든 요청을 혼자서 처리함.
- 단일 데이터베이스: 모든 상품 정보와 결제 데이터를 저장함.
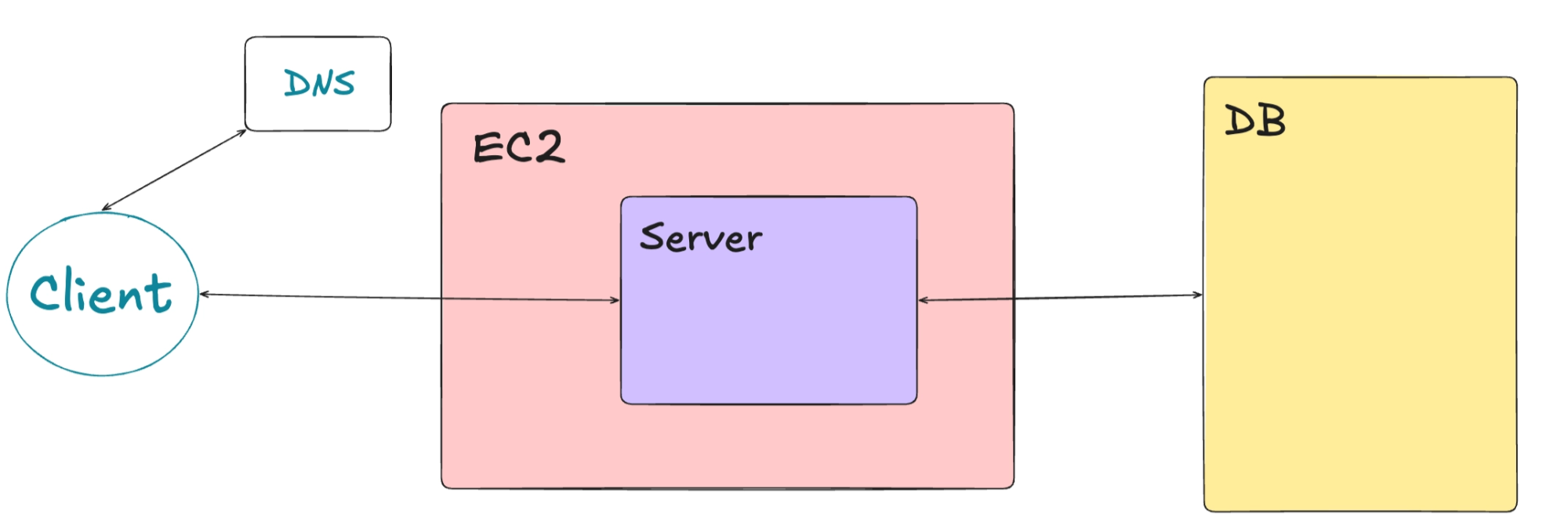
3. 상황
3.1 서버가 다운된다면?
현재의 단일 서버 구조에선 서버가 멈추면 다른 인프라가 살아있어도, 서비스가 다운된다. 문제는 서버가 “혼자서” 모든 요청을 처리하고 있다는 것이다.
해결방안:
- 여러 서버를 두고, ALB로 트래픽 분산한다.
- 이때 EC2들은 서로 다른 AZ에 분산하는걸 추천한다. 만약 하나의 AZ에 몰아넣었다가, 해당 AZ가 고장나면 가용성을 위해 분산한 서버가 의미 없어진다.
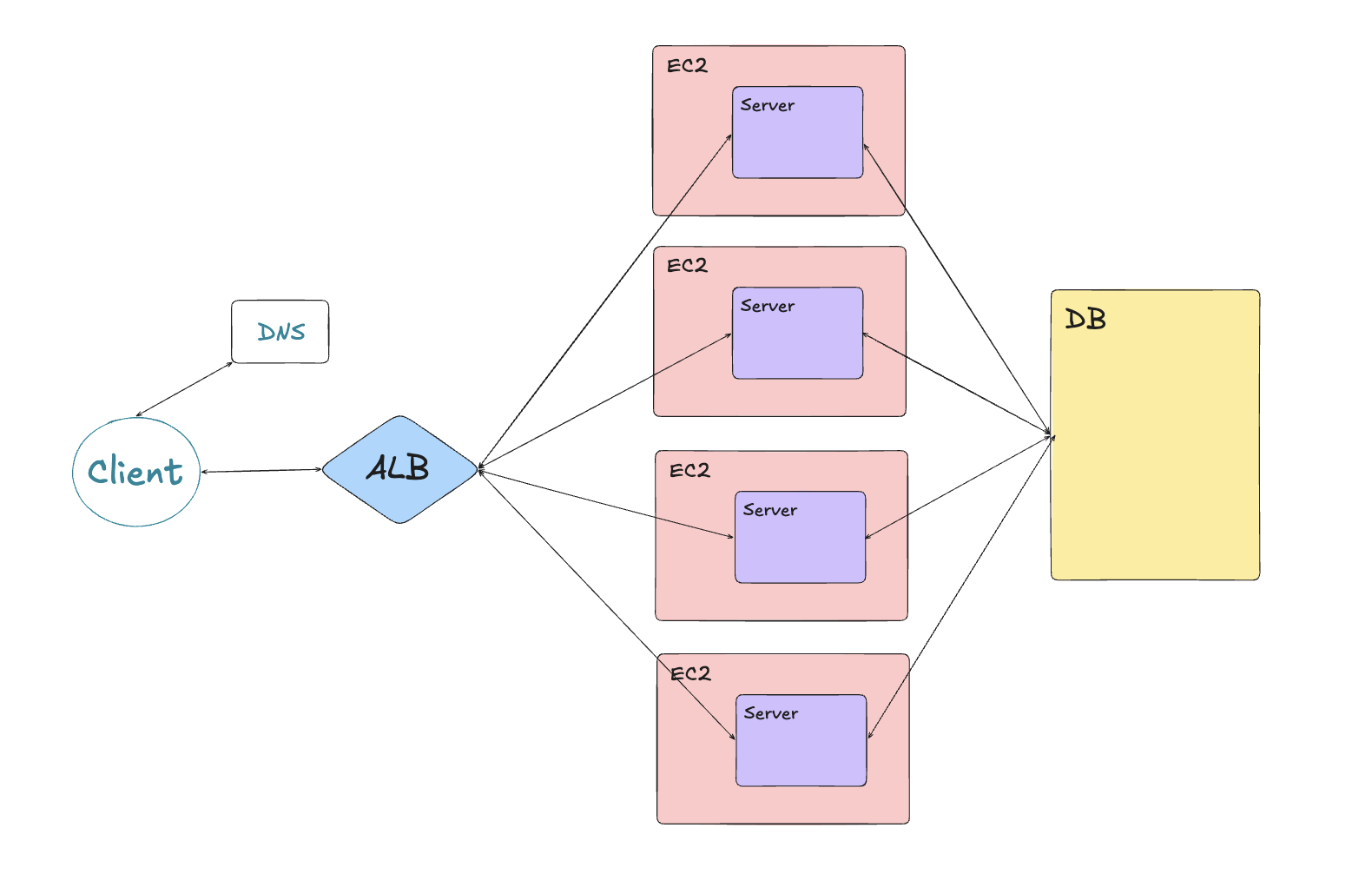
한계점:
- 서버 간 메모리를 공유하지 못하는 문제가 있다. 만약 유저 관리에 Session을 사용중이라면, 1번 서버로 로그인한 유저가 다음 요청을 2번 서버로 날릴 때, 로그인 정보가 없어지는 문제가 있을 수 있다.
- 로그도 각각 서버에 따로 쌓이기 때문에 중앙화 해야한다.
- 신규버전 배포 시, 어떻게 모든 서버를 한 번에 변경할지도 고려해야한다.
3.2 ALB가 고장난다면?
이제 서버가 몇 개 죽어도, 똑똑한 ALB가 알아서 살아있는 서버로 트래픽을 분산해준다.
하지만 여전히 같은 문제가 있다. 뒤에 서버가 몇 개가 있다 한들, 앞에서 트래픽을 분산해주는 ALB가 고장나면 말짱 꽝이다.
해결방안:
ALB를 여러개로 분산한다. 사실 AWS의 ALB를 사용한다면 ALB의 스케일링은 자동으로 된다.
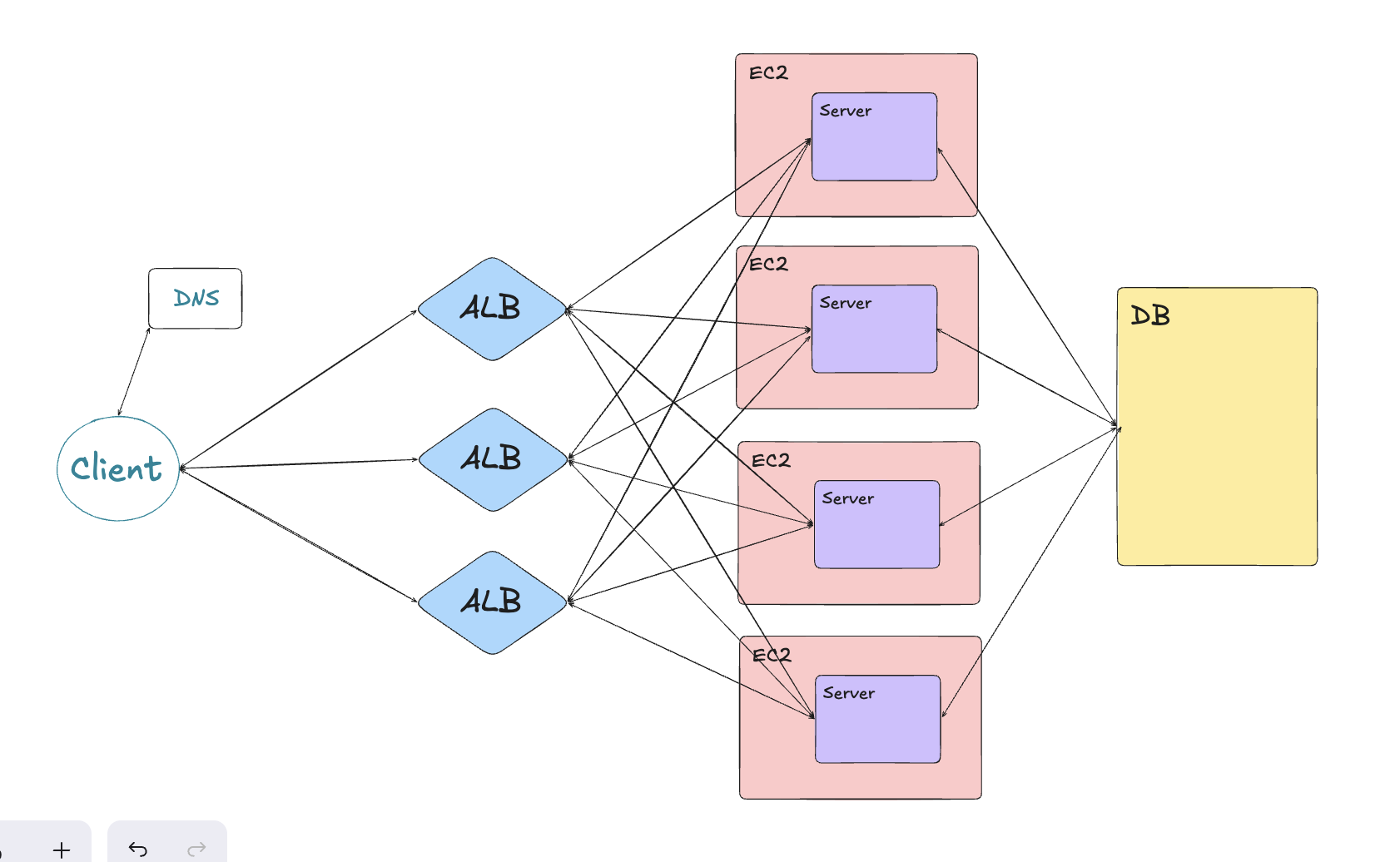
3.3 DB가 멈춘다면?
이제 서버가 몇 개 죽어도, ALB가 몇 개 작동하지 않아도, 우리 클라이언트는 안전하게 응답을 받을 수 있다.
하지만 서버가 늘어나도 모두 하나의 DB를 바라보고 있다면, DB 역시 SPOF가 된다.
DB의 SPOF를 해결하는 방법은 정말 많다! 그 중에 Master - Replica 방법을 대표로 설명한다.
(여러 대의 서버는 하나의 서버로 단순화한다. 실제로 DB는 여러 서버와 통신하고 있다고 생각해야한다.)
해결 방안:
- 읽기 DB, 쓰기 DB를 분리한다. (= Master - Replica)
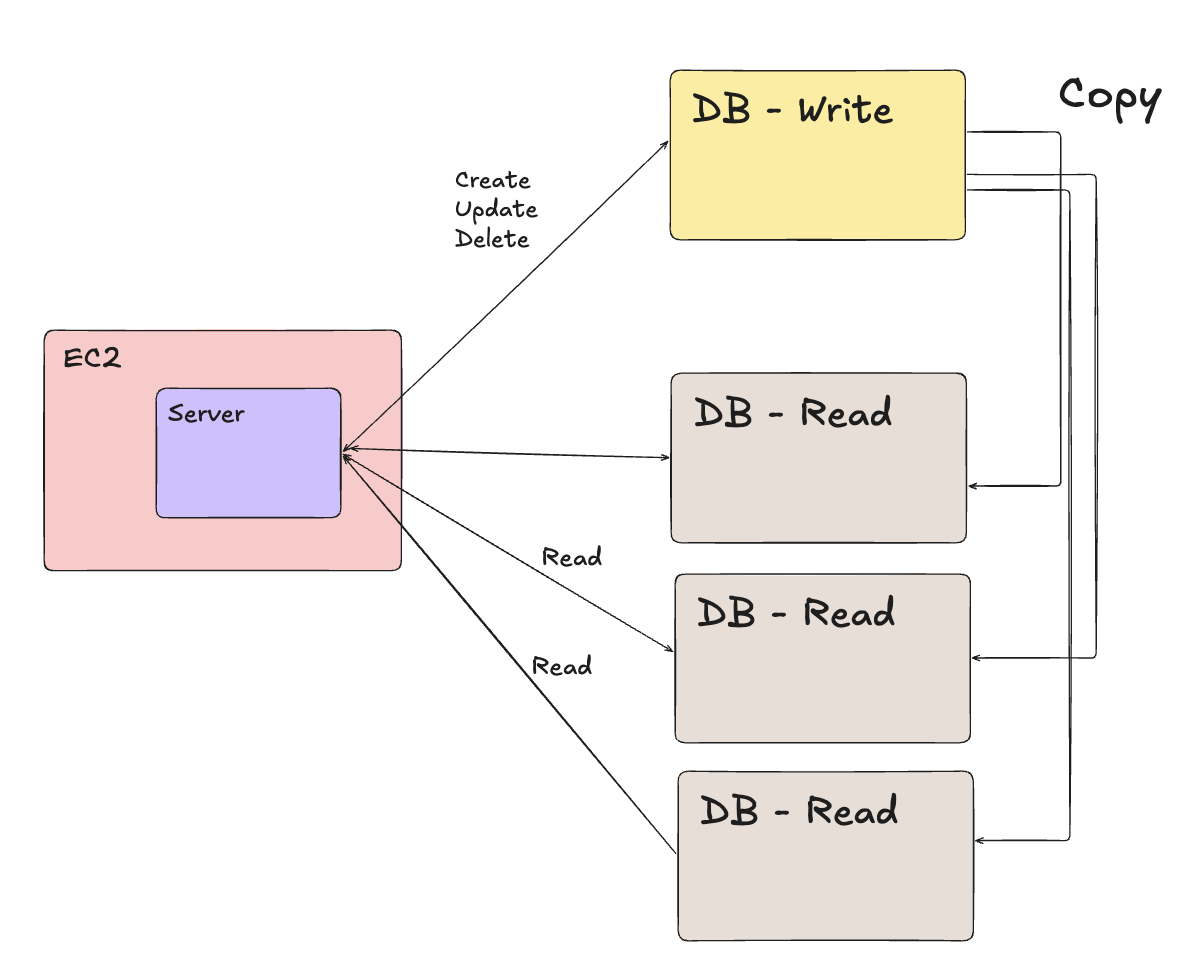
눈치가 빠르다면 바로 한계점을 느낄 수 있다.
한계점:
- 실제로 SPOF를 해결했다기보단, 부하 분산에 가까움. 그래도 시스템이 한 번에 작동이 멈추진 않음.
- 만약 Master DB(
DB - Write)가 멈춘다면, 쇼핑몰의 후기 작성 등의 쓰기 작업은 멈추지만, 상품을 둘러보는 읽기 작업은 멈추지 않음.
- 만약 Master DB(
- 쓰기 DB에 작업을 했다면 읽기 DB로 복제해주는 시간이 필요하다. (복제 지연)
3.4 Master DB가 멈춘다면?
쓰기 작업을 못하게 되면, 사실상 시스템이 다운된 것이나 다름 없다. 따라서 이에 대한 복구 방안이 필요하다. 이를 장애 극복(Failover) 시스템 이라고 한다.
해결방안1: Replica DB 중 하나를 Master DB로 격상시킨다. 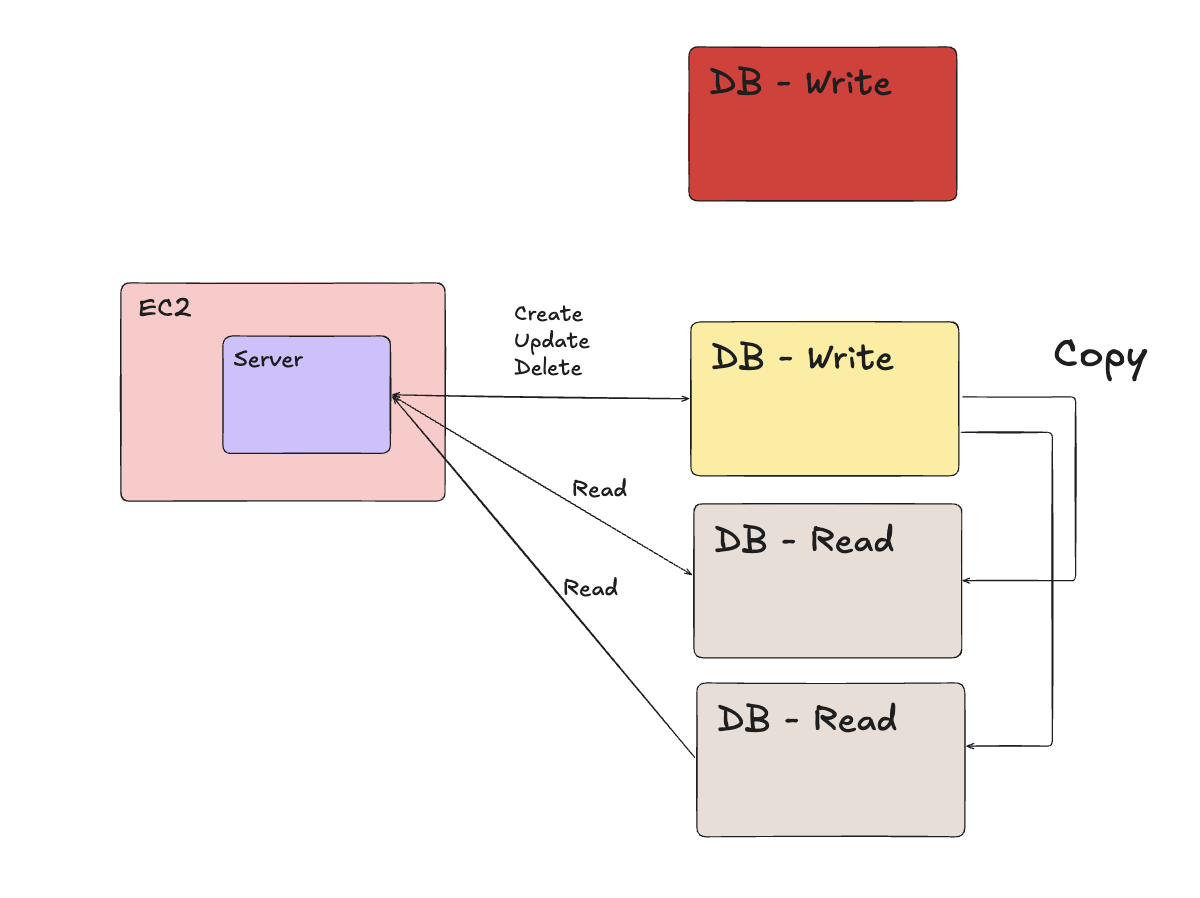
해결방안2: Write DB용 Standby DB를 운용하다가 장애 시 변경한다.
평소
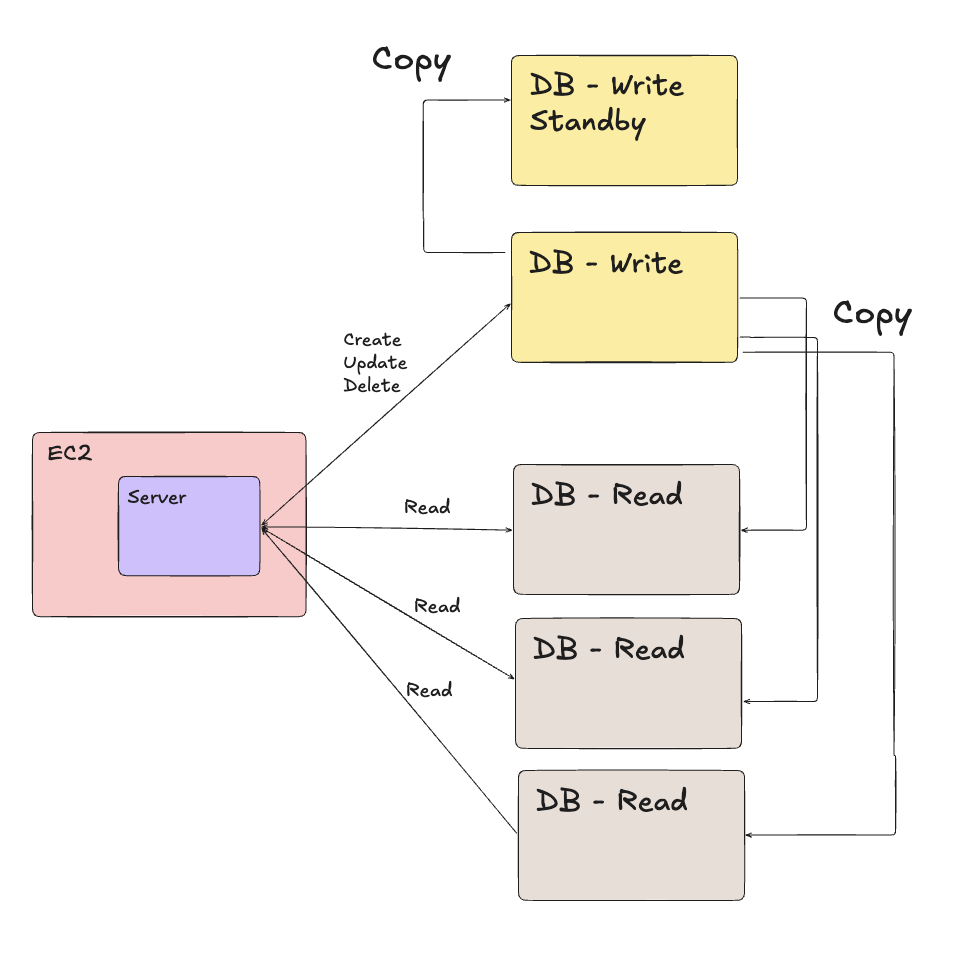
Failover
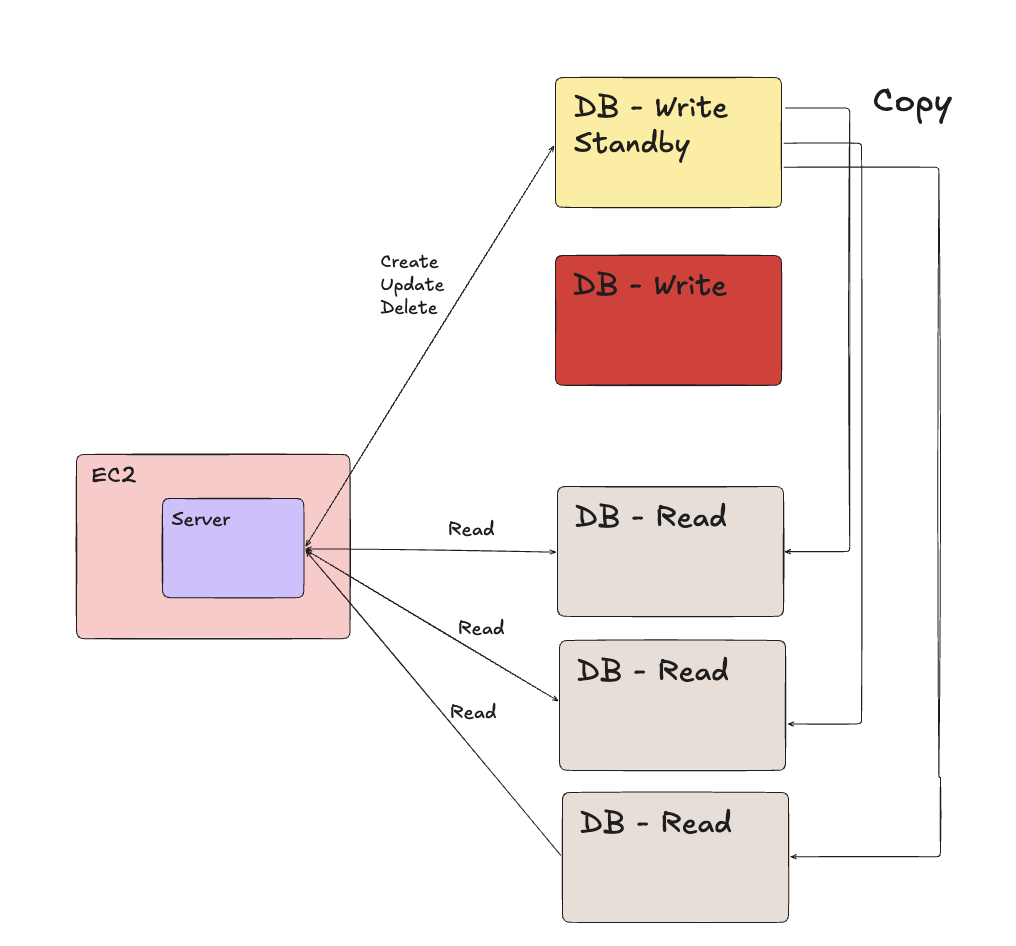
- 평소에 Standby DB는 유저의 트래픽을 아예 받지 않고, 오로지 Write DB을 복사하기만 한다. 만약 트래픽을 받는다면 유저의 트래픽과, Write DB의 복사 작업 사이에서 락, 자원 경합, 데이터 정합성 등의 문제가 날 수 있다.
- DB SPOF 해결 방법은 이것 외에도 여러 개 있다! 이것은 다른 글에서 다뤄보도록…
- 한계점
- DB 교체 시, 애플리케이션이 더 이상 죽은 DB로 쿼리를 보내지 않도록 변경해주어야 한다.
- 미리 연결해둔 커넥션 풀도 무용지물이 된다.
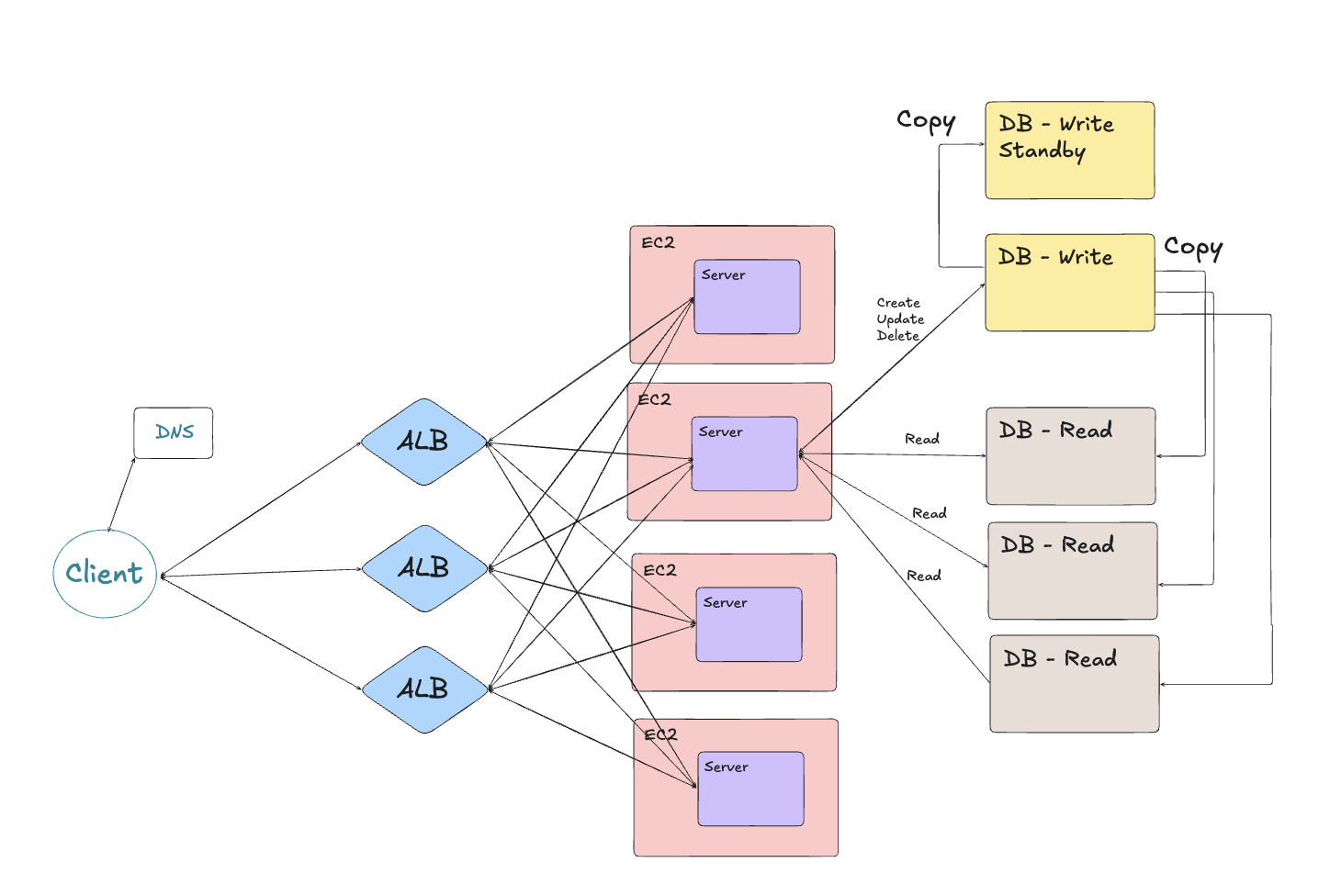
최종 인프라 예상도
서버와 DB의 연결은 단순화한다. 실제로는 모든 서버에서 모든 DB로 작업이 이루어진다.
결론
고가용성 목표는 “사용자가 불편하지 않을 안정적인 서비스” 제공이다.
각각의 한계점을 보면 알겠지만, 안정적인 서비스를 위해 인프라를 늘릴수록 역설적이게도 관리 포인트가 늘어나 관리가 어려워진다.
늘어난 인프라의 숫자만큼 비용도 올라간다.
정답은 무턱대고 인프라를 도입하는 것이 아니라, 우리 서비스에 적합한 인프라를 도입하는 것이다.
만약 서버가 자주 죽는 문제를 로그에서 발견했다면 서버의 확장을 먼저 고려할 수도 있고, DB IO가 많아 병목이 자주 생긴다면 DB의 확장을 먼저 고려할 수 있다. 모든 위치의 문제를 해결하는 것은 그 다음이다.
일단 서비스 목표를 잡아두고(예시: 가동 시간 연중 99%) 그것을 달성하기 위한 인프라를 하나씩 도입하는게 순서에 맞는 듯 싶다.
참고로 구글에선 해당 용어를 이렇게 정의하고 있다.
예를 들어 SLO가 99.9% 라면, 서비스는 연간 8.7시간 정도의 장애를 허용하는 것이고, 이를 달성하기 위한 인프라를 구축해야 한다.