[AI] LLM 기반 챗봇 4 : Text Splitters

[Caution] 해당 게시글은 유튜브 모두의 AI 님의 영상 정리와 제 사견이 들어있습니다.
0. 이전 글
1. Text Splitters란?
하나의 문서를 LLM의 토큰 제한에 걸리지 않고, 여러 문장을 참고해 답변할 수 있도록 문서를 분할하는 역할을 한다. LLM은 주로 토큰 제한이 있기 때문에(ex 4096자) 필수적인 작업이다.
하나의 청크는 하나의 다차원 벡터값이 되어 벡터 스토어에 저장된다. 이때 청크는 문서를 Text Splitter를 통해 나눈 하나의 덩어리를 뜻한다.
추후 질문에 대해 가장 유사한 벡터를 찾는 것이 핵심 기능이 되기 때문에 청크를 나누는 작업은 매우 중요하다고 생각한다.
2. Text Splitter의 종류
2.1 CharacterTextSplitter
구분자 1개를 기준으로 분할한다. 하나의 구분자를 기준으로만 청크를 분할하기 때문에 최대 토큰 제한을 지키지 못하는 경우도 발생한다.
2.2 RecursiveCharacterTextSplitter
여러개의 구분자를 기준으로 재귀적으로 분할하기 때문에 최대 토큰 제한을 지키기 수월하다.
제일 먼저 줄바꿈(\n\n)으로 문서를 분할하고 분할한 청크가 최대 토큰 제한보다 큰 경우 재귀적으로 문장 단위(\n)로 분할한다. 그럼에도 불구하고 청크 사이즈가 큰 경우 단어 단위로 자르게 된다.
단어 단위로 자르는 경우는 흔치 않으므로, 결국 이 방법이 문장들의 의미를 최대한 유지한 채 분할하게 만들고, LLM에 활용함에 있어서 맥락이 유지되게 하는 용이한 방법이다.
대부분의 경우 RecursiveCharacterTextSplitter를 사용한다.
3. 사용 예시
3.1 CharacterTextSplitter
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
data = PyPDFLoader("path")
pages = data.load_and_split()
text_splitter = CharacterTextSplitter(
separator="\n", # 구분자
chunk_size = 50, # 청크 사이즈
chunk_overlap = 5, # 앞 뒤로 겹치게 할 범위
length_function = len, # chunksize의 기준 -> len = 글자수 기준
)
texts = text_splitter.split_documents(pages)
char_list = []
for i in range(len(texts)):
char_list.append(len(texts[i].page_content))
print(char_list)
코드에서는 50문자를 기준으로 청크를 분할하도록 설정했지만 실행 결과를 보면 50개를 넘어가는 경우도 많다. 이런 경우 최대 토큰 제한을 지키지 못할 경우도 생길 것이다.

나눈 청크들의 글자 길이를 출력해봤다. 기준은 50자이지만, 50자를 넘는 청크를 심심치않게 찾아볼 수 있다.
3.2 RecursiveCharacterTextSplitter
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
data = PyPDFLoader("/Users/yuseokhyeon/langch/history_of_seoul.pdf")
pages = data.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 50, # 청크 사이즈
chunk_overlap = 5, # 앞 뒤로 겹치게 할 범위
length_function = len, # chunksize의 기준 -> len = 글자수 기준
)
texts = text_splitter.split_documents(pages)
char_list = []
for i in range(len(texts)):
char_list.append(len(texts[i].page_content))
print(char_list)
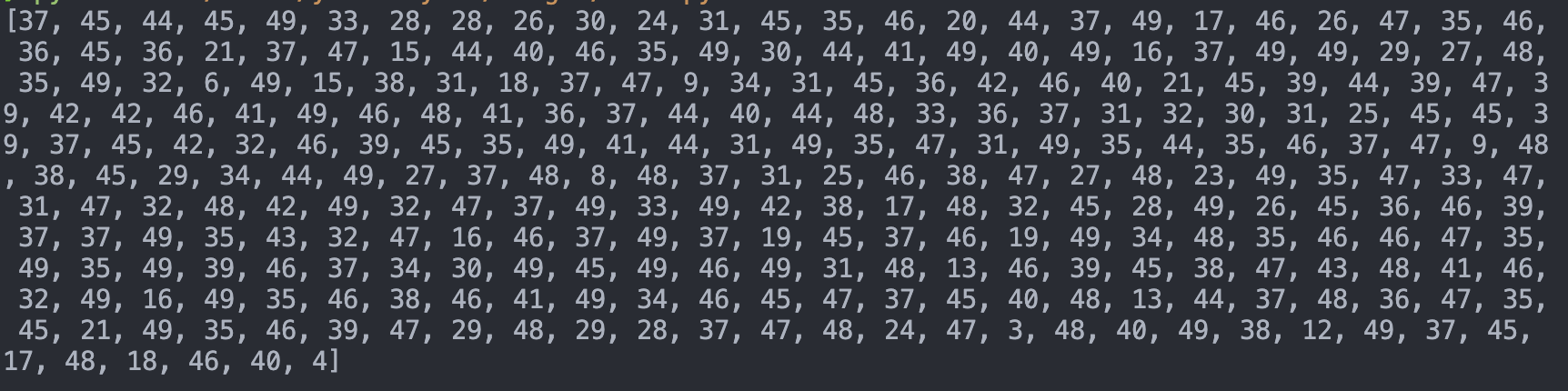
같은 문서에 대해 같은 설정으로 청크를 나누었다. 실행 결과를 보면 칼 같이 50개를 넘는 청크가 하나도 없는 것을 볼 수 있다.ㄴ
4. 기타 Splitters
일반적인 글로 된 문서는 모두 상기한 TextSplitter를 통해 나눌 수 있지만, code 혹은 latex, html 같이 컴퓨터 언어로 작성된 문서는 TextSplitter로 처리하기 애매하다.
이런 경우엔 특수한 Splitter가 필요하다. 예를 들어 python으로 작성된 코드의 경우 def 혹은 class 등으로 문서를 나누는게 효과적일 것이다.
1
2
3
4
5
6
7
8
from langchain.text_splitter import(
RecursiveCharacterTextSplitter,
Language
)
sp = RecursiveCharacterTextSplitter.get_separators_for_language(Language.PYTHON)
print(sp)
 파이썬에서 사용하는 구분자를 가져와 봤다. class, def, 줄바꿈 등이 있다.
파이썬에서 사용하는 구분자를 가져와 봤다. class, def, 줄바꿈 등이 있다.
5. 토큰 단위 텍스트 분할기
위에서 설명한 text 분할의 목적은 LLM이 해당 청크를 이해할 수 있게 나누는 것이다. 하지만 글자수를 기준으로 분할한 경우 이후 LLM에서 사용하지 못할 수도 있다. 그렇기 때문에 token 단위로 나누었을 경우 확실하게 사용할 수 있다.
token이라는 것은 텍스트와 달리 트랜스포머에서 처리하는 방식에 따라 수가 달라질 수 있다. 예를 들어 GPT 모델은 tiktoken이라는 토크나이저를 기반으로 텍스트를 토큰화 한다. 그렇기 때문에 GPT를 사용한다면 tiktoken encoder를 기반으로 텍스트를 토큰화 하는 것이 효과적이라고 볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import tiktoken
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
data = PyPDFLoader("path")
pages = data.load_and_split()
tokenizer = tiktoken.get_encoding("cl100k_base")
def tiktoken_len(text): # 토큰을 세는 함수
tokens = tokenizer.encode(text)
return len(tokens)
print(tiktoken_len(pages[1].page_content)) # 텍스트의 토큰 갯수
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 50, # 청크 사이즈
chunk_overlap = 5, # 앞 뒤로 겹치게 할 범위
length_function = tiktoken_len, # 토큰 갯수를 기준으로 나눠줌. -> 토큰이 50개 이하가 되도록 나눔
)
texts = text_splitter.split_documents(pages)
# 두번째 청크의 각각 글자 갯수와 토큰 갯수
print(len(texts[1].page_content))
print(tiktoken_len(texts[1].page_content))