[AI] LLM 기반 챗봇 5 : Text Embeddings

[Caution]해당 게시글은 유튜브 모두의 AI 님의 영상 정리와 제 사견이 들어있습니다.
1. Text Embeddings란?
Text Embedding은 앞서 Text Splitters로 나눈 청크들을 숫자로 변환해 LLM이 문장 간 유사성을 비교할 수 있게 변경해주는 역할을 한다.
앞서 말했듯 청크들을 벡터로 바꾸고, 또한 사용자 질문도 벡터로 변경해 사용자 질문의 벡터와 가장 거리가 짧은( = 가장 유사한) 문장을 찾아 가공해 답변하도록 한다.
즉 문장이라는 비정형 데이터를 활용할 수 있게 정형 데이터로 바꾸는 역할이다.
2. Text Embeddings 작동 방식
2.1 문장 간 유사성을 찾는 방식
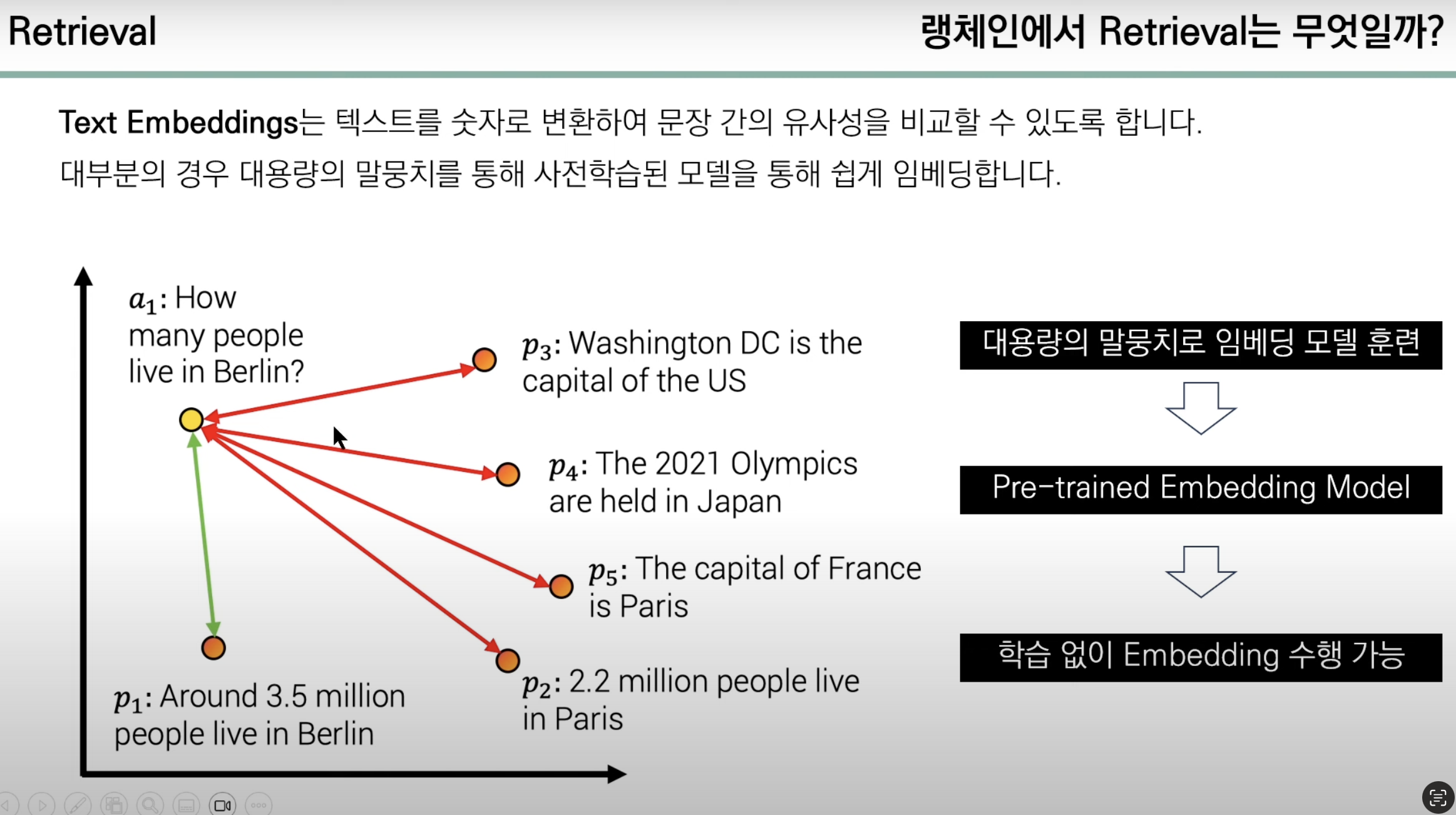
사진 출처 : 유튜브 모두의 AI
해당 그림을 보면 이해가 쉽다. 그림에선 설명에 용이하도록 2차원 평면에서 가장 가까운 점을 매칭하지만 사람이 사용하는 문장들은 매우 복잡하기에 실제 Text Embedding 된 벡터들은 다차원을 갖고 있을 것이다.
하지만 2차원이든 N차원이든 벡터간 거리를 구하는 것은 어렵지 않으므로 두 벡터 간 거리만 구하면 된다.
2.2 수치로 바꾸는 과정
그렇다면 비정형 문장들을 어떤 과정을 통해 정형화 된 수치로 변경하는 것일까?
이때는 이미 존재하는 대용량의 말뭉치로 학습한 모델을 사용할 수 있다. 이런 모델들을 가져다 사용한다면 별도의 학습 없이 Embedding 을 수행 가능하다. 그렇다면 어떤 언어(한국어, 영어, 일본어 등등…)로 훈련됐는지가 중요할 것이다.
2.3 Embedding 모델 종류
| 구분 | 기업명 | 모델명 | 장점 | 단점 |
|---|---|---|---|---|
| 유료 모델 | OpenAI, Cohere, Amazon | text-embeddig-ada-002, embed-multilingual-v2.0, titan-embed-text-v1 | 편리한 사용, 많은 언어 지원, GPU 불필요 | 비용 발생, 보안 우려 |
| 무료 모델 | HuggingFace | bge-large-en-v1.5, multilingual-e5-large, ko-sbert-nil, koSimCSE-roberta-multitask | 무료, 보안 우수 | 사용이 어려움, 언어가 제한됨, GPU 필요 |
무료 모델에는 한국어 전용 Embedding 모델도 존재한다. 한국어 모델은 볼드 처리를 해놓았다.
3. 코드
3.1 OpenAI
그렇다면 실제로 사용해보자
[Caution] Openai api key는 호출할때마다 비용을 지불해야한다. 일정 이상 과금하지 않도록 주의하자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from langchain_community.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key = "your key")
embeddings = embeddings_model.embed_documents(
[
"안녕하세요",
"제 이름은 홍길동입니다.",
"당신의 이름은 무엇인가요?",
"Hello World",
"만나서 반갑습니다."
]
)
print(len(embeddings))
print(len(embeddings[0]))

출력으로 임베딩한 문장의 갯수와 “안녕하세요” 라는 문장의 벡터 수를 지정했다.
문장 5개가 임베딩됐고, 안녕하세요 라는 문장은 1536차원의 벡터로 변환됐다.
다음으로는 각각의 문장에 대한 임베딩과 문장에 대한 유사도를 확인해보자.
이때 벡터간 유사도를 판별하는 함수는 cosine similarity이다. 코사인 유사도에 대한 정보는 아래 링크에서 확인해 볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
from langchain_community.embeddings import OpenAIEmbeddings
import numpy as np
from numpy.linalg import norm
embeddings_model = OpenAIEmbeddings(openai_api_key = "your key")
embeddings = embeddings_model.embed_documents(
[
"안녕하세요",
"제 이름은 홍길동입니다.",
"당신의 이름은 무엇인가요?",
"Hello World",
"만나서 반갑습니다."
]
)
embedded_query_q = embeddings_model.embed_query("이 대화에서 언급된 이름은 무엇입니까?")
embedded_query_a = embeddings_model.embed_query("이 대화에서 언급된 이름은 홍길동입니다.")
def cos_sim(A, B): # cosine similarity
return np.dot(A, B) / (norm(A) * norm(B))
print(cos_sim(embedded_query_q, embedded_query_a))
print(cos_sim(embedded_query_q, embeddings[1]))
print(cos_sim(embedded_query_q, embeddings[3]))

첫 번째 출력값은 이 대화에서 언급된 이름은 무엇입니까? 와 이 대화에서 언급된 이름은 홍길동입니다. 의 유사도 값이다. 90.1% 이상의 높은 유사도를 보여준다.
두 번째 출력값은 이 대화에서 언급된 이름은 무엇입니까? 와 제 이름은 홍길동입니다. 의 유사도이다. 84.9% 의 높은 유사도를 보여준다.
세 번째 출력값은 이 대화에서 언급된 이름은 무엇입니까? 와 Hello World 의 유사도이다. 위의 두 유사도보다 낮은 72%를 보여준다. 서로 연관이 낮은 문장인 만큼 값이 낮게 나왔다.
3.2 Local (HuggingFace)
로컬에서 사용하는 만큼 비용 걱정없이 사용 가능하다
[Caution] 무슨 이유에서인지 모르겠지만 로컬에서 실행하면 segmentation fault 가 난다. 괜히 Openai를 사용하는게 아니다. 이하 실습에선 colab에서 진행했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
import numpy as np
from numpy.linalg import norm
model_name = "BAAI/bge-small-en"
model_kwargs = {'device' : 'cpu'}
encode_kwargs = {'normalize_embeddings' : True}
hf = HuggingFaceBgeEmbeddings(
model_name = model_name,
model_kwargs = model_kwargs,
encode_kwargs = encode_kwargs
)
embeddings = hf.embed_documents(
[
"today is monday.",
"weather is nice today",
"what's the problem",
"langchain in useful",
"Hello world.",
"my name is morris"
]
)
BGE_query_q = hf.embed_query("Hello? who is this?")
BGE_query_a = hf.embed_query("Hi this is harrison")
def cos_sim(A, B): # cosine similarity
return np.dot(A, B) / (norm(A) * norm(B))
print(cos_sim(BGE_query_q, BGE_query_a))
print(cos_sim(BGE_query_q, embeddings[1]))
print(cos_sim(BGE_query_q, embeddings[5]))

첫번째 출력 : 질문과 답변이 가장 높은 유사도를 보여준다.
두번째 출력 : 질문과 관련없는 답변의 경우 74.6% 정도의 유사도이다.
세번째 출력: 어느정도 관련 있지만 애매한? 경우 79% 정도의 유사도이다.
물론 질문에 따라 유사도가 달라지긴 했지만, 이정도로 충분한가? 싶은 차이이긴 하다.
다음은 한국어 문장에 대해서 학습해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
from langchain_community.embeddings import HuggingFaceEmbeddings
import numpy as np
from numpy.linalg import norm
model_name = "jhgan/ko-sbert-nli"
model_kwargs = {'device' : 'cpu'}
encode_kwargs = {'normalize_embeddings' : True}
hf = HuggingFaceEmbeddings(
model_name = model_name,
model_kwargs = model_kwargs,
encode_kwargs = encode_kwargs
)
sentences =[
"안녕하세요",
"제 이름은 홍길동입니다.",
"당신의 이름은 무엇입니까?",
"랭체인은 유용합니다.",
"홍길동의 아버지 이름은 홍상석 입니다."
]
ko_embeddings = hf.embed_documents(sentences)
q = "홍길동은 아버지를 아버지라 부르지 못했습니다. 홍길동의 아버지 이름은 무엇입니까?"
a = "홍길동의 아버지는 엄했습니다."
ko_query_q = hf.embed_query(q)
ko_query_a = hf.embed_query(a)
def cos_sim(A, B): # cosine similarity
return np.dot(A, B) / (norm(A) * norm(B))
print(cos_sim(ko_query_q, ko_query_a))
print(cos_sim(ko_query_q, ko_embeddings[1]))
print(cos_sim(ko_query_q, ko_embeddings[3]))
print(cos_sim(ko_query_q, ko_embeddings[4]))

첫번째 출력 : 질문과 답의 연관성이다. 연관이 없는 만큼 45% 정도의 유사도이다.
두번째 출력 : 이름의 질문은 있지만, 홍길동의 아버지 이름을 알려주진 않는다. 53% 정도의 유사도이다.
세번째 출력 : 아예 관계 없는 두 문장이다. 2%의 유사도이다.
네번째 출력 : 가장 관계 있는 문장이다. 60%의 유사도를 보여준다.
여기선 다루지 않지만 가장 먼저 실행한 영어 모델을 사용해 한국어 문장을 embedding할 경우 값이 제대로 나오지 않는다. 즉 언어에 맞는 모델을 찾는 것이 매우 중요하다고 볼 수 있다.