[AI] LLM 기반 챗봇 6 : Vectorstores

[Caution]해당 게시글은 유튜브 모두의 AI 님의 영상 정리와 제 사견이 들어있습니다.
1. Vectorstores란?
앞서서 Text Embeddings를 통해 청크들을 정형화된 수치로 바꾸는 작업을 수행했다. 이 과정은 방대한 문서들을 벡터로 바꾸기 때문에 시간과 비용이 많이 소요된다. LLM과 query를 주고받을때마다 이 과정을 수행하는 것은 비용적 측면, 시간적 측면에서 매우 비효율적이기 때문에 한번 벡터화한 수치들을 DB에 저장한 후 이용하는것이 효과적이다.
이 과정에서 벡터들을 저장, 이용하도록 하는 도구가 Vectorstore 다.
이번 실습에서 사용해볼 DB는 Chroma, FAISS 가 있다.
2. 코드
2.1 Chroma
Chroma는 오픈소스로 무료로 사용 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import tiktoken
from langchain.text_splitter import RecursiveCharacterTextSplitter
tokenizer = tiktoken.get_encoding("cl100k_base")
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)
from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("/content/drive/MyDrive/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0, length_function = tiktoken_len)
docs = text_splitter.split_documents(pages)
from langchain_community.embeddings import HuggingFaceEmbeddings
model_name = "jhgan/ko-sbert-nli"
model_kwargs = {'device' : 'cpu'}
encode_kwargs = {'normalize_embeddings' : True}
hf = HuggingFaceEmbeddings(
model_name = model_name,
model_kwargs = model_kwargs,
encode_kwargs = encode_kwargs,
)
db = Chroma.from_documents(docs, hf)
query = "6대 먹거리 산업은?"
docs = db.similarity_search(query)
print(docs[0].page_content)

앞서 Text Embeddings 실습에선 코사인 유사도를 직접 정의해서 비교했지만, Chroma DB에선 db.similarity_search 를 통해 간단하게 가장 유사한 문장을 찾아준다.
이때 찾아준 객체는 Document 객체로 되어있기 때문에 page_content 와 metadata를 다 포함하고 있다.
하지만 앞서 말했던 것 처럼 계산한 벡터들을 저장해서 실행하는것이 효과적이다.
1
2
3
# Drive에 저장
db2 = Chroma.from_documents(docs, hf, persist_directory = "./chroma_db")
docs = db2.similarity_search(query)
해당 코드를 통해 원하는 장소에 bd를 만드는 것이 가능하다.
from_documents(문서, 모델, persist_directory = db 생성 경로)
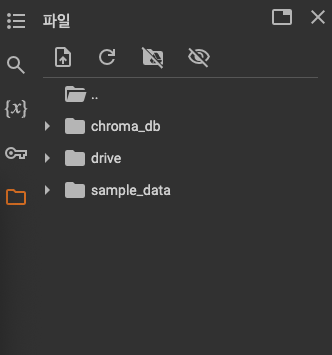
chroma_db가 생성된 것을 확인할 수 있다.
Drive에 저장했다면 불러와서 활용해보자
1
2
3
4
# Drive에서 불러오기
db3 = Chroma(persist_directory= "./chroma_db", embedding_function= hf)
docs = db3.similarity_search(query)
print(docs[0].page_content)

Chroma(persist_directory= 경로, embedding_function= 모델) 로 불러올 수 있다.
정상적으로 잘 불러와진다.
또한 Chroma db에선 query와 불러온 문서가 어느 정도의 유사도를 갖고 있는지 비교하는 함수 similarity_search_with_score()를 지원한다.
1
2
3
4
docs = db3.similarity_search_with_relevance_scores(query, k=3) # k = 상위 k개의 문서를 반환
print("가장 유사한 문서: \n\n {}\n\n". format(docs[0][0].page_content))
print("문서 유사도\n {}".format(docs[0][1]))
similarity_search_with_relevance_scores() 를 사용한다면 유사도 상위 k개의 문서를 반환 가능하다.

반환값은 2차원 배열로 주어지며, [ ([Document 객체],[Score]), … ] 형식을 하고 있다.
2.2 FAISS
FAISS는 Facebook AI 유사성 검색의 약자로, 고밀도 벡터의 효율적인 유사성 검색 및 클러스터링을 위한 라이브러리이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
from langchain_community.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain_community.document_loaders import TextLoader
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("/content/drive/MyDrive/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0, length_function = tiktoken_len)
docs = text_splitter.split_documents(pages)
from langchain_community.embeddings import HuggingFaceEmbeddings
model_name = "jhgan/ko-sbert-nli"
model_kwargs = {'device' : 'cpu'}
encode_kwargs = {'normalize_embeddings' : True}
ko = HuggingFaceEmbeddings(
model_name = model_name,
model_kwargs = model_kwargs,
encode_kwargs = encode_kwargs,
)
db = FAISS.from_documents(docs, ko)
query = "인공지능 산업구조는 어떻게 구성되어있어?"
docs = db.similarity_search(query)
print(docs[0].page_content)
사용 방식은 Chroma와 크게 다른 점은 없는듯 하다.
FAISS 역시 similarity_search를 통해 벡터 유사도를 검색 가능하다.

1
2
docs_and_scores = db.similarity_search_with_score(query)
docs_and_scores

similarity_search_with_socre를 사용하면 상위 유사도의 문서 몇 개를 보여주는것 같다.
하지만 Chroma에서 사용한 with_relevance_socre 와 다르게 FAISS의 with_score는 점수가 낮을수록 유사한 문서이다. 즉 벡터의 거리값인듯 하다.
FAISS 역시 local에 저장 가능하다.
1
db.save_local("faiss_index")
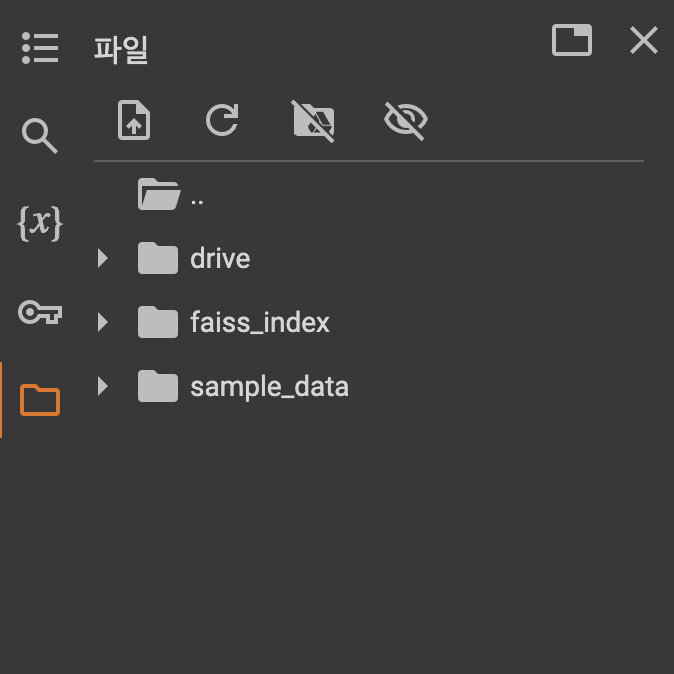
정상적으로 저장됐다.
벡터를 불러올 때는 load_local을 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
new_db = FAISS.load_local("faiss_index", ko, allow_dangerous_deserialization=True)
query = "인공지능 산업구조는 어떻게 구성되어 있어?"
docs = new_db.similarity_search_with_relevance_scores(query, k=3)
print("질문: {} \n".format(query))
for i in range(len(docs)):
print("{0} 번째 유사 문서 유사도 \n{1}".format(i+1, round(docs[i][1],2)))
print("------------------------------------------------------------")
print(docs[i][0].page_content)
print("\n")
print(docs[i][0].metadata)
print("------------------------------------------------------------")
with_relevance_socres를 사용한다면 점수와 함께 유사한 문서를 뽑아준다. 사용 방법은 Chroma와 완전이 동일한 것 같다.
max_marginal_relevance_search를 사용한다면 유사한 문서 중에서 서로 다양한 문서를 뽑을 수 있다.