[DB] SQLModel로 데이터베이스 다루기 <4>

공식문서 참조
1. 연관된 테이블 만들기
지금까지는 단 하나의 테이블에서만 데이터를 불러왔다. 하지만 서로 연관없는 데이터들을 분리하기 위해 테이블을 여러개로 나누는 경우가 많다. 예를 들어보자
Hero table
| id | name | secret_name | age | team_name | headquarters | team_id |
|---|---|---|---|---|---|---|
| 1 | Ironman | Stark | 40 | Avangers | LA | 1 |
| 2 | C.America | Rogers | 100 | Avangers | LA | 1 |
| 3 | Spiderman | Parker | 17 | Avangers | LA | 1 |
| 4 | Batman | Wayne | 41 | J.League | California | 2 |
| 5 | Superman | Kent | 500 | J.League | California | 2 |
이 Hero 테이블에서 속해있는 히어로 팀 데이터는 중복되고 있는 것을 볼 수 있다. 또한 해당 데이터들은 팀에 대한 데이터지, 히어로와는 별 관련이 없다. 이런 데이터들을 아래와 같이 분리할 수 있다.
Hero table
| id (Primary Key) | name | secret_name | age | team_id (Foreign Key = team.id) |
|---|---|---|---|---|
| 1 | Ironman | Stark | 40 | 1 |
| 2 | C.America | Rogers | 100 | 1 |
| 3 | Spiderman | Parker | 17 | 1 |
| 4 | Batman | Wayne | 41 | 2 |
| 5 | Superman | Kent | 500 | 2 |
Team table
| id (Primary Key) | name | headquarters |
|---|---|---|
| 1 | Avangers | LA |
| 2 | J.League | California |
한눈에 보기 쉬워졌다. 이런 데이터를 SQLModel로 만드는 방법을 알아보자
1.1 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from sqlmodel import Field, SQLModel
class Team(SQLModel, table = True):
id: int | None = Field(default = None, primary_key = True)
name: str = Field(index = True)
headquarters: str
class Hero(SQLModel, table = True):
id: int | None = Field(default = None, primary_key = True)
name: str = Feild(index = True)
secret_name: str
age: int | None = Field(default=None, index=True)
team_id: int | None = Field(default=None, foreign_key="team.id")
이때 외래키 foreign_key는 문자열로 지정해주고, 대문자가 아닌 소문자 team.id로 해준다.
2. 연관된 테이블에 데이터 넣기
POST를 통해 테이블에 데이터를 넣어보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@app.post("/", status_code=status.HTTP_201_CREATED)
async def create_heros(session:Annotated[AsyncSession, Depends(get_async_session)]):
team1 = Team(name="Avangers", headquarters="LA")
team2 = Team(name="J.League", headquarters="California")
async with session.begin():
session.add_all([team1, team2])
hero_1 = Hero(name="Ironman", secret_name="Stark", age=40, team_id=team1.id)
hero_2 = Hero(name="C.America", secret_name="Rogers", age=100, team_id=team1.id)
hero_3 = Hero(name="Spiderman", secret_name="Parker", age=17, team_id=team1.id)
hero_4 = Hero(name="Batman", secret_name="Wayne", age=41, team_id=team2.id)
hero_5 = Hero(name="Superman", secret_name="Kent", age=500, team_id=team2.id)
async with session.begin():
session.add_all([hero_1, hero_2, hero_3, hero_4, hero_5])
return {"msg": "Heros created"}
이때 외래에서 불러올 키가 반드시 DB에 먼저 존재해야 하는듯 싶다. 아래와 같이 한번에 커밋하려하면 team_id 가 Null 값으로 들어간다.
1
2
3
4
## team_id가 Null로 들어가는 코드. 이렇게 하면 안됨
async with session.begin():
session.add_all([team1, team2])
session.add_all([hero_1, hero_2, hero_3, hero_4, hero_5])
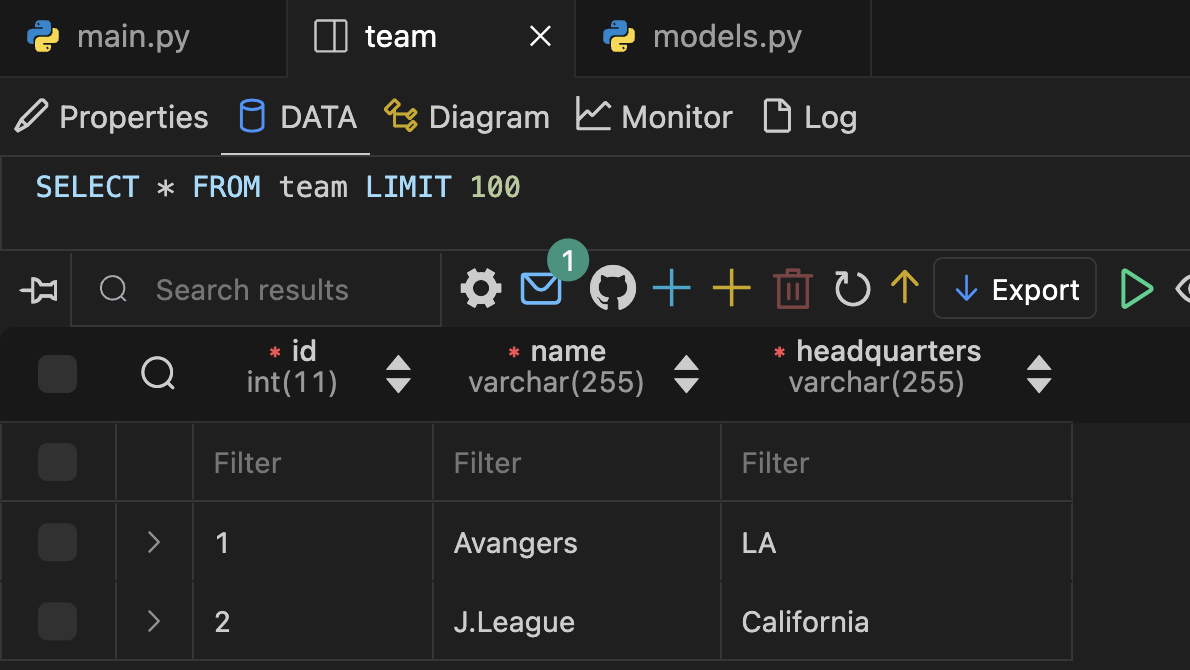

값이 제대로 들어간 것을 볼 수 있다.
3. 연관된 테이블에서 데이터 조회 JOIN
테이블을 나누어 중복된 데이터를 제거한것 까지는 좋다. 하지만 이런 경우라면 어떨까?
3.1 단일 조회
“나는 spiderman이 어떤 히어로 팀에 속했는지 알고 싶어”
Hero 테이블만 봤을 때는 팀의 id만 알 수 있다. 그 id가 어느 팀을 가리키는지는 알지 못한다.
Team 테이블만 봤을 때는 히어로가 어디에 속했는지 알 수 없다.
즉 동시에 두 테이블을 한번에 조회해야 한다. 이때 사용하는 메서드가 join() 이다.
1
2
3
4
5
6
7
@app.get("/", status_code=status.HTTP_200_OK)
async def get_heros(session:Annotated[AsyncSession, Depends(get_async_session)]):
statement = select(Team).join(Hero).where(Hero.name == "Spiderman")
results = await session.exec(statement)
hero = results.one_or_none()
return hero
select 로 조회할 테이블을 고른 후,
join 으로 조건을 설정할 테이블을 고른다.
그 이후 where 로 join 에서 고른 테이블의 열을 지정해 준다.
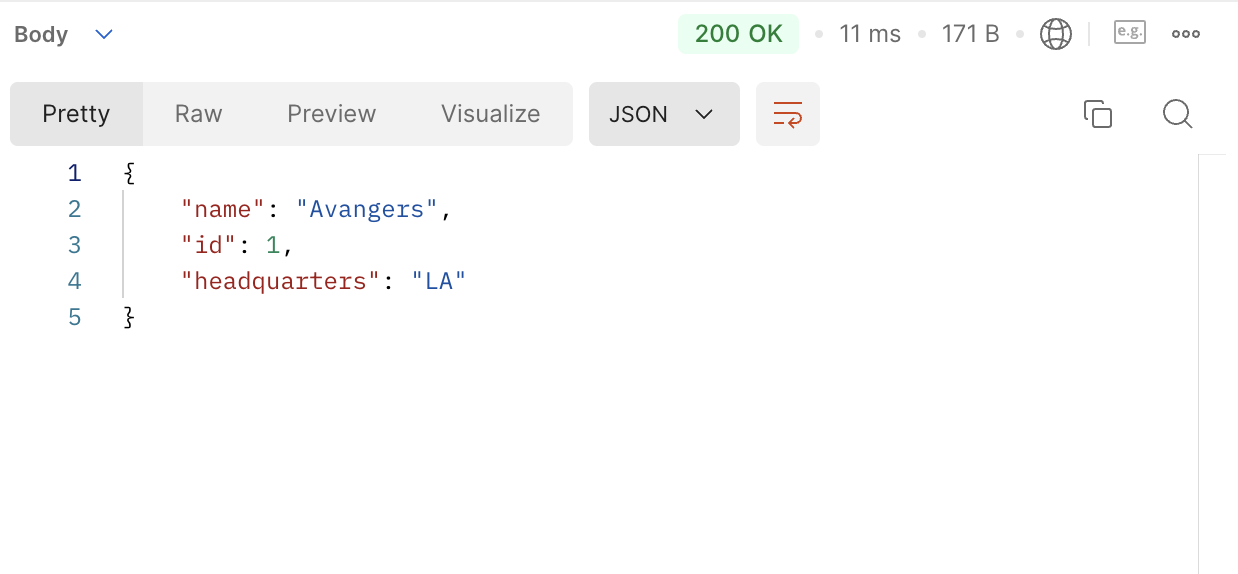
Spiderman 이 어떤 히어로 팀에 속했는지 조회됐다.
3.2 여러개 조회
여러 데이터를 조회하는 것도 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@app.get("/", status_code=status.HTTP_200_OK)
async def get_heros(session:Annotated[AsyncSession, Depends(get_async_session)]):
statement = select(Hero, Team).join(Team)
results = await session.exec(statement)
heros = results.fetchall()
response = []
for hero, team in heros:
response.append({
"hero": hero.model_dump(), # SQLModel 객체를 dict로 변환
"team": team.model_dump()
})
return response
이때 주의점. select 를 통해 2개 이상의 테이블을 조회할 때, heros를 반드시 dict로 직렬화 해주어야 한다.
단일 테이블의 데이터의 경우 이미 SQLModel 로 선언한 모델이라 자동으로 직렬화되어 출력되지만, 두개를 붙인 경우 tuple의 형태가 되기 때문이다.
이 경우엔 특별한 조건 없이 두 데이터를 조회했다. 두 테이블은 이미 team_id로 묶여있기 때문에 가능하다.
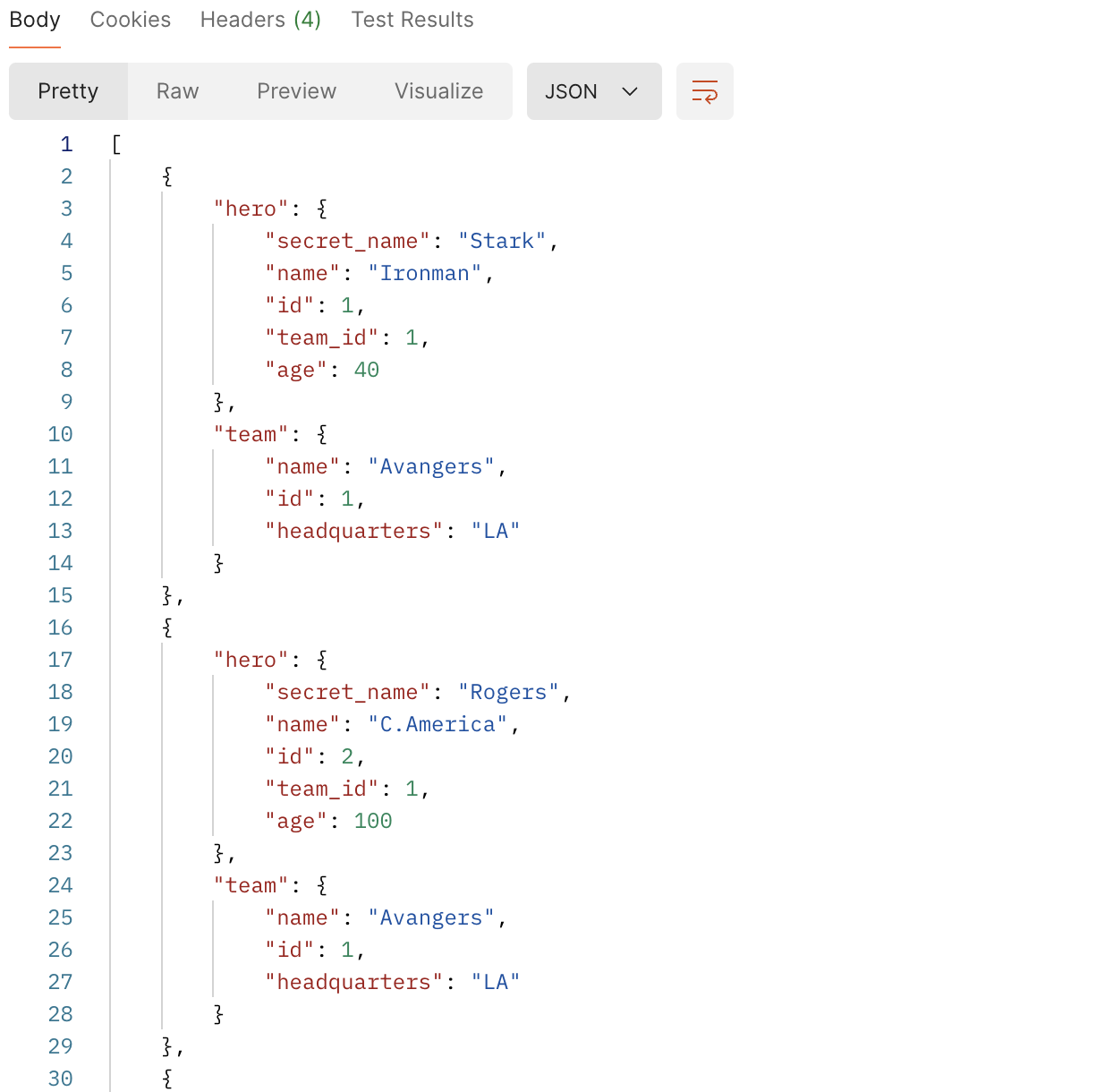
두 테이블이 합쳐져서 조회된다.